SQL 코딩 테스트를 위한 SELECT문 정리(지속적으로 업데이트)
24 Feb 2021사진으로 첨부한 테스트 데이터는 모두 아래 링크에서 실습
https://www.w3schools.com/sql/trysql.asp?filename=trysql_select_all
🔷 전체 구문 🔷
SELECT [ALL | DISTINCT] 컬럼명 [,컬럼명...]
FROM 테이블명 [,테이블명...]
[WHERE 조건식]
[GROUP BY 컬럼명 [HAVING 조건식]]
[ORDER BY 컬럼명]
🔹 SELECT 뒤에는 항상 FROM이 따라와야 한다.
→ SELECT 컬럼명1, 컬럼명2, … FROM 테이블명1, 테이블명2, …
🔷 전체 컬럼 조회 🔷
SELECT * FROM [테이블명]
🔷 특정 컬럼 조회 🔷
🔹 컬럼은 1개만 조회할 수도 있고, 여러 개를 조회할 수 있음
SELECT 컬럼명 FROM [테이블명]
SELECT 컬럼명, 컬럼명, ... FROM [테이블명]
🔹 AS: 컬럼에 별칭 부여
SELECT A AS AA, B, C FROM [테이블명]
# A,B,C 컬럼을 조회하면서 A 컬럼에 AA라는 별칭 부여
🔹 ALL: 테이블에 동일한 데이터 행이 있는 경우에도 모든 데이터를 반환(default) |
DISTINCT: 테이블에 동일한 데이터 행이있는 경우 중복을 제거한 1 개만 조회 |
SELECT [ALL | DISTINCT] 컬럼명 FROM 테이블명
🔷 WHERE 🔷
SELECT [컬럼명] FROM [테이블명] WHERE 조건식
🔹 원하는 레코드(row)만 검색
🔹 조건식 안에 숫자나 연산자를 제외한 문자는 ’‘로 감싸야 됨
🔹 비교 연산자 (=, ≠, >, ≥, <, ≤)
🔹 수치 비교, 문자열 비교 모두 가능
🔹 논리 연산자 (AND, OR, NOT)
→ 우선순의 NOT > AND > OR
🔹 IS NULL: 지정되지 않은 레코드 조회
→ 공백은 문자열이고, 0은 숫자이므로 NULL과는 다름
🔹 컬럼명 BETWEEN A AND B
/* 직원 테이블에서 급여가 2000(이상)~3000(이하)인 직원 검색 */
SELECT * FROM 직원 테이블 WHERE 급여 BETWEEN 2000 AND 3000;
/* 직원 테이블에서 급여가 2000 미만, 3000 초과 직원 검색 */
SELECT * FROM 직원 테이블 WHERE 급여 NOT BETWEEN 2000 AND 3000
🔹 IN
/* 직원 테이블에서 직급이 사원, 대리, 과장인 직원만 검색 */
SELECT * FROM 직원 테이블 WHERE 직급 IN ('사원', '대리', '과장');
/* 직원 테이블에서 직급이 사원, 대리, 과장을 제외한 직원만 검색 */
SELECT * FROM 직원 테이블 WHERE 직급 NOT IN ('사원', '대리', '과장');
🔹 LIKE: 문자열 패턴 매칭 (with %, _ 등)
/* text 열에 'It's'을 포함하는 행을 검색 */
/* '를 문자열 상수 안에 포함할 경우 2개를 연속해서 기술 */
SELECT * FROM sample WHERE text LIKE 'It''s'
/* 이름이 A로 시작하는 사람만 검색 */
SELECT * FROM 테이블 WHERE 이름 LIKE 'A%'
/* 이름에 A가 들어가는 사람만 검색 */
SELECT * FROM 테이블 WHERE 이름 LIKE '%A%'
/* 이름에 A가 들어가지 않는 사람만 검색 */
SELECT * FROM 테이블 WHERE 이름 NOT LIKE '%A%'
/* 이름의 두 번째 자리가 A인 사람만 검색 */
SELECT * FROM 테이블 WHERE 이름 LIKE '_A'
/* 이름이 3글자인 사람만 검색 */
SELECT * FROM 테이블 WHERE 이름 LIKE '___'
🔷 ORDER BY 🔷
🔹 조회한 레코드들을 지정한 컬럼들을 기준으로 정렬
SELECT * FROM 테이블 ORDER BY 컬럼명 [ASC | DESC]
🔹 ASC(ascending order): 오름차순 정렬(default)
🔹 DESC(dscending order): 내림차순 정렬
🔹 컬럼명을 여러 개 지정하면, 앞의 컬럼 레코드 값이 동일한 경우 작성한 순서대로 다음 컬럼의 레코드 값을 기준으로 정렬
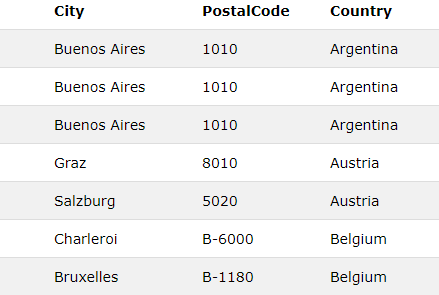
/* Customers 테이블에서 Country 기준으로 오름차순 정렬하고 같은 경우, PostalCode를 기준으로 내림차순 정렬 */
SELECT * FROM Customers ORDER BY Country ASC, PostalCode DESC
https://www.w3schools.com/sql/trysql.asp?filename=trysql_select_all
🔹 LIMIT [시작 위치], 개수 : 조회할 레코드 수를 제한. 시작 위치는 index 0부터 시작
/* CustomerID가 1부터 n까지 있을 때*/
/* 상위 3개만 출력*/
SELECT CustomerID FROM Customers ORDER BY CustomerID LIMIT 3
> 1
> 2
> 3
/* 상위 3번째 레코드부터 3개만 출력*/
SELECT CustomerID FROM Customers ORDER BY CustomerID LIMIT 1,3
> 2
> 3
> 4
🔷 날짜 및 시간 함수 🔷
🔹 YEAR : 연도 추출
🔹 MONTH : 월 추출
🔹 DAY : 일 추출
🔹 HOUR : 시 추출
🔹 MINUTE : 분 추출
🔹 SECOND : 초 추출
문제 출처: 프로그래머스-SQL 고득점 Kit
SELECT DISTINCT HOUR(DATETIME) AS HOUR, COUNT(*)
FROM ANIMAL_OUTS
WHERE HOUR(DATETIME) BETWEEN 9 AND 19
GROUP BY HOUR
ORDER BY HOUR
🔷 NULL 변환(치환) 함수 🔷
🔹 NULL을 0 또는 다른 값으로 변환하기 위해서 사용하는 함수
🔹 IFNULL(컬럼,'변환할 값'): mysql에서 사용
🔹 NVL(컬럼, '변환할 값'): oracle에서 사용
🔹 COALESCE(컬럼,'변환할 값'): 모두 사용 가능
🔹 문제 참고: 프로그래머스 NULL 처리하기
/* mysql 기준 같은 결과 값을 나타냄*/
SELECT ANIMAL_TYPE, COALESCE(NAME, "No name"), SEX_UPON_INTAKE FROM ANIMAL_INS
ORDER BY ANIMAL_ID
SELECT ANIMAL_TYPE, IFNULL(NAME, "No name"), SEX_UPON_INTAKE FROM ANIMAL_INS
ORDER BY ANIMAL_ID
🔷 CASE 함수 🔷
CASE
WHEN 조건 THEN 반환 값
WHEN 조건 THEN 반환 값
ELSE 반환 값
END
🔹 중첩 IF ELSE와 유사한 구조
🔹 WHEN과 THEN은 한 쌍
🔹 ELSE가 존재하지 않고, 조건에 맞지 않아서 반환 값이 없으면 NULL를 반환
🔹 문제 참고: 프로그래머스-중성화 여부 파악하기
/*보호소의 동물이 중성화되었는지 아닌지 파악하려 합니다.
중성화된 동물은 SEX_UPON_INTAKE 컬럼에 'Neutered' 또는 'Spayed'라는 단어가 들어있습니다.
동물의 아이디와 이름, 중성화 여부를 아이디 순으로 조회하는 SQL문을 작성해주세요.
이때 중성화가 되어있다면 'O', 아니라면 'X'라고 표시해주세요.*/
SELECT ANIMAL_ID, NAME,
CASE
WHEN SEX_UPON_INTAKE LIKE "%Neutered%" THEN 'O'
WHEN SEX_UPON_INTAKE LIKE "%Spayed%" THEN 'O'
ELSE 'X'
END AS "중성화"
FROM ANIMAL_INS
ORDER BY ANIMAL_ID
🔷 그룹 함수 🔷
🔹 하나 이상의 행을 그룹으로 묶어 연산하여, 하나의 결과를 나타내는 함수
🔹 COUNT: 레코드 수 계산
🔹 MAX: 최대 값을 가지는 레코드 반환
🔹 MIN: 최소 값을 가지는 레코드 반환
🔹 SUM: 레코드 총 합
🔹 AVG: 레코드 평균
/* https://www.w3schools.com/sql/trysql.asp?filename=trysql_select_all */
/* 위 링크의 Products 테이블 사용 */
/* 전체 레코드 수 */
SELECT COUNT(*) FROM Products
>> 77
/* Price 컬럼의 레코드 수(만약 Price에 NULL 값이 있었다면 무시되어 값이 달랐을 수 있음) */
SELECT COUNT(Price) FROM Products
>> 77
/* 중복되는 값을 제거한 레코드 수 */
SELECT COUNT(DISTINCT Price) FROM Products
>> 62
SELECT MAX(Price) AS price_max, MIN(Price) AS price_min FROM Products
>> price_max|price_min
>> 263.5|2.5
SELECT SUM(Price) AS price_sum, AVG(Price) AS price_avg FROM Products
>> price_sum|price_avg
>> 2222.71|28.866363636363637
🔷 GROUP BY 🔷
🔹 특정 컬럼을 기준으로 그룹화하여 테이블에 존재하는 행들을 그룹별로 구분
🔹 SELECT절 뒤에 조회할 컬럼들 중 그룹화 하지 않을 컬럼이 존재하더라도 꼭 모두 GROUP BY절 뒤에 적어줘야 함(컬럼이 달라도 개수만 맞으면 오류는 안남)
/* SELECT DISTINCT City FROM Customers 와 동일 */
SELECT City FROM Customers GROUP BY City
/* Country를 그룹별로 Country, City 레코드를 조회 */
SELECT Country, City FROM Customers GROUP BY Country, City

/* 그훕화 한 뒤, 그 그룹 내에서 City를 내림차순 정렬 */
/* Country ASC를 해주지 않으면 City를 기준으로만 정렬하기 때문에 Country 레코드가 보기 불편함 */
/* 그룹화한 의미가 거의 없어짐 */
SELECT Country, City FROM Customers GROUP BY Country, City ORDER BY Country ASC, City DESC

🔹 GROUP BY절은 그룹 함수와 같이 사용했을 때 더 가치있는 정보를 만들 수 있음
/* ProductName 별 Price 평균 */
SELECT ProductName, AVG(Price) FROM Products GROUP BY ProductName
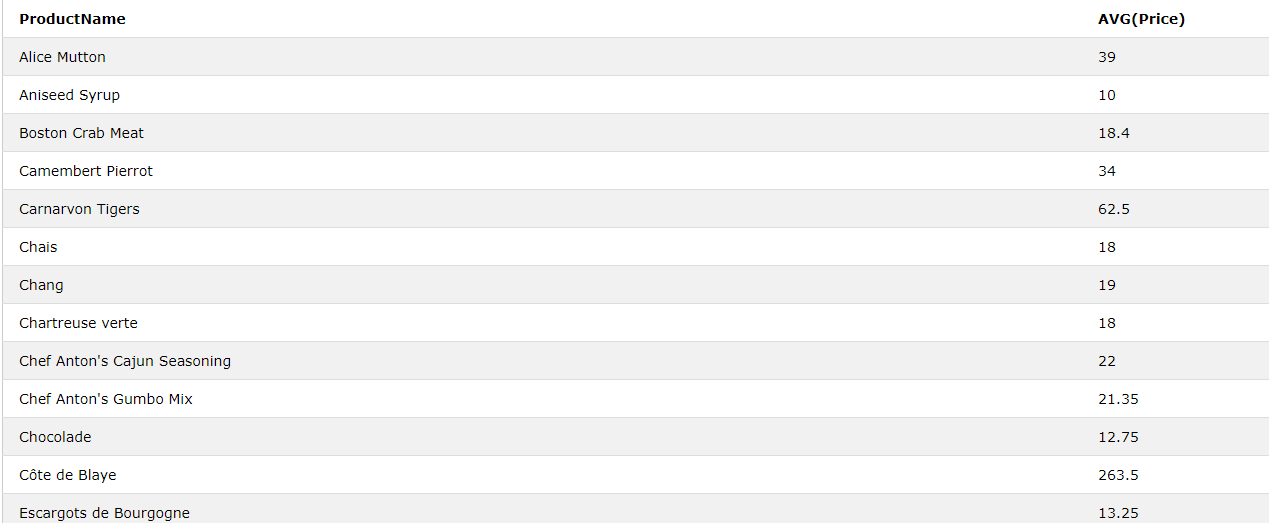
/* ProductName 별 Price 평균이 높은 순서대로 */
/* 이때는 Price만 정렬하는 것이 더 가치있음 */
SELECT ProductName, AVG(Price) FROM Products GROUP BY ProductName ORDER BY Price DESC

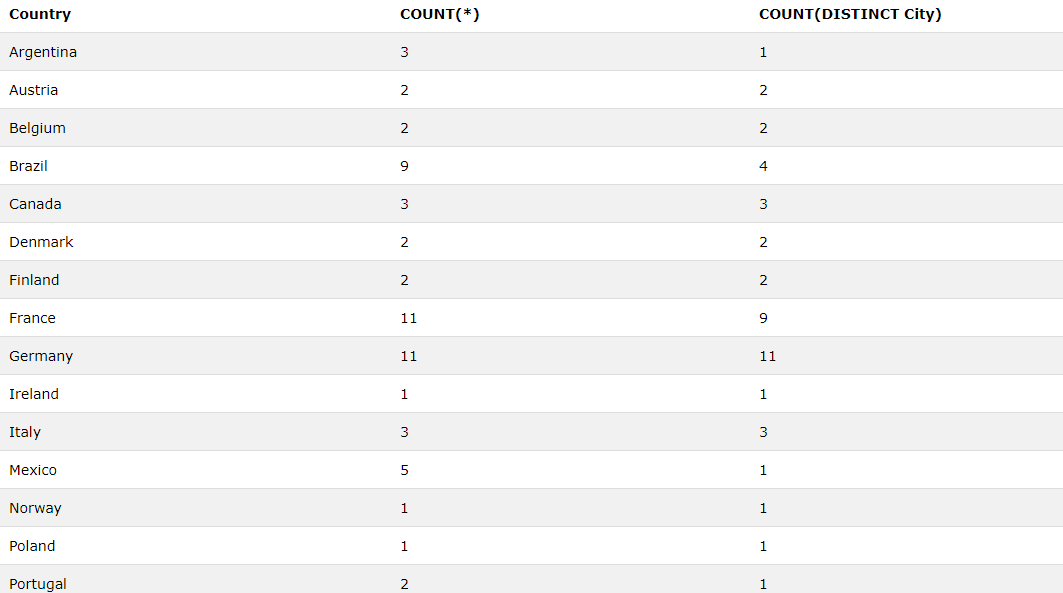
/* 나라 별 고객 수와 도시 종류 */
SELECT Country, COUNT(*), COUNT(DISTINCT City) FROM Customers GROUP BY Country
🔷 HAVING 🔷
🔹 GROUP BY 절에 의해 생성된 결과 값 중 원하는 조건에 부합하는 레코드만
🔹 그룹 함수 사용 가능
SELECT ProductName, AVG(Price) FROM Products
GROUP BY ProductName
HAVING AVG(Price) >= 20
/* 아래처럼 별칭을 주면 더 편함 */
/* SELECT ProductName, AVG(Price) AS price FROM Products */
/* GROUP BY ProductName */
/* HAVING price >= 20 */

🔷 JOIN 🔷
🔹 두 개 이상의 테이블이나 데이터베이스를 연결하여 데이터를 검색
🔹 보통 Primary key혹은 Foreign key로 두 테이블을 연결
공부 자료: 생활 코딩 / 실습 자료: sql join 연습장 / JOIN 벤 다이어그램: https://sql-joins.leopard.in.ua/

🔹 INNER JOIN: JOIN 하는 모든 테이블에 존재하는 레코드만 JOIN
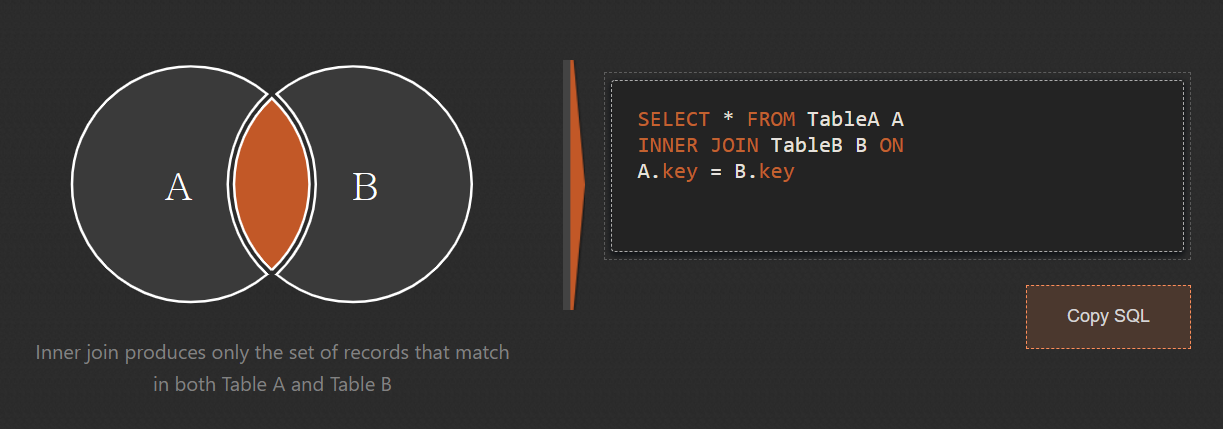
/* *로 조회했기 때문에 모든 컬럼이 표시
topic 테이블 마지막 레코드 author_id 값이 NULL이며,
author 테이블의 마지막 레코드인 aid 3은 topic이 참조하지 않고 있으므로,
각 레코드는 제외된다. */
SELECT * FROM topic
INNER JOIN author ON topic.author_id = author.aid

🔹 LEFT JOIN: 왼쪽 테이블의 모든 레코드를 기준으로 JOIN, 없는 레코드는 NULL로 표시

SELECT * FROM topic
LEFT JOIN author
ON topic.author_id = author.aid

/* 3개의 테이블을 LEFT JOIN
앞의 두 테이블을 먼저 topic 테이블을 기준으로 author 테이블을 LEFT JOIN 후,
그 결과에 profile 테이블을 LEFT JOIN */
SELECT tid, topic.title, author_id, name, profile.title AS job_title
FROM topic
LEFT JOIN author ON topic.author_id = author.aid
LEFT JOIN profile ON author.profile_id = profile.pid;

🔹 FULL OUTER JOIN: LEFT JOIN한 후 RIGHT JOIN한 다음 중복되는 레코드를 삭제. 이를 지원하지 않는 SQL에서는 LEFT JOIN한 결과와 RIGHT JOIN한 결과를 UNION해서 사용

SELECT * FROM topic
FULL OUTER JOIN author ON topic.author_id = author.id

🔹 EXCLUSIVE (LEFT) JOIN: 한 쪽 테이블에 존재하는 레코드만 조회

/* topic을 기준으로 LEFT 조인 후 author가 NULL인 레코드만 조회 */
SELECT * FROM topic
LEFT JOIN author ON topic.author_id = author.aid
WHERE author.aid is NULL

REFERENCE
https://ko.wikipedia.org/wiki/Select_(SQL)
https://extbrain.tistory.com/46
https://www.w3schools.com/sql/trysql.asp?filename=trysql_select_all
https://programmers.co.kr/learn/challenges
https://sql-joins.leopard.in.ua/